
こんにちは、SRE の中村です。
ユニファでは SLI/SLO が設計されておらず、Slack の監視アラート通知チャンネルに通知が来ていなければ健全、アラートが来たらどこか異常の可能性あり、というように、健全性の定量的指標がありませんでした。
どんどんプロダクト数が増え、機能も増え、より複雑性が増す中でこのままの状態を続けるのは SRE として黙っていられない。
という思いが少しばかりと、あとは単純に SLI/SLO を運用してみたいという好奇心から PJ を発足しました。
私自身、SLI/SLO の運用経験は全くありませんでしたので、Google SRE や他社様の事例を参考にさせていただき、見よう見まねで進めました。
同じように SLI/SLO の設計をしたいけれど、何から手をつけたら良いか分からず困っている方にとって、少しでも参考になったら幸いです。
概念
まずはそれぞれの用語の説明です。
SLI(Service Level Indicator)
サービスレベル指標。サービスのパフォーマンスを測定するための具体的なメトリクス。
カテゴリ例:
- 可用性:正常なHTTPレスポンス(2xx, 3xx)の割合
- レイテンシ:リクエストの応答時間(95パーセンタイル、99パーセンタイル)
具体的なメトリクス例:
- 可用性:
(成功リクエスト数 / 総リクエスト数) × 100 - レスポンスタイム:
(閾値秒以内にレスポンスを返したリクエスト数 / 総リクエスト数) × 100
SLO(Service Level Objective)
サービスレベル目標。SLIに対する具体的な数値目標。
SLO例:
- 可用性SLO:月次可用性99.9%以上(月間43分以下のダウンタイム)
- レイテンシSLO:95%のAPIリクエストが500ms以内に応答
具体的な設定例:
- Webサイト:99%のページが2秒以内に読み込み完了
- データベース:99.9%のクエリが100ms以内に応答
- API:月次可用性99.95%、95%のリクエストが500ms以内に応答
重要な原則:
過度に達成しすぎない(コストが増加する可能性)
- 例:99.9%のSLOなら月間43分のダウンタイムが許容される
- 100%を目指すと過度な冗長化・慎重な運用でイノベーションが阻害される
平均値ではなくパーセンタイル値を使用
- 平均値の2つの問題(例:100件中95件が100ms、残り5件が5000ms ⇒ 平均 345ms)
- ① 大多数の実態が歪む:95%は100msでも異常値に引っ張られて全体が遅く見える
- ② 深刻な遅延が隠れる:5000msの遅延が正常値に薄められ、「平均345msなら許容範囲」と見過ごされる
- パーセンタイル値で計測した場合:p95, p99 で計測すると、「95%のリクエストが100ms」「しかしp99は5000ms(一部で致命的な遅延が発生)」のように実態を正確に把握できる
- 平均値の2つの問題(例:100件中95件が100ms、残り5件が5000ms ⇒ 平均 345ms)
依存サービスのSLA制約:自社のSLOは依存しているサービスのSLAを上回ることはできない(後述)
エラーバジェット(Error Budget)
SLOで許容される失敗の量。(100% - SLO)
例:
- 可用性 SLO 99.9% → エラーバジェット 0.1%(月間43分のダウンタイムを許容)
- 可用性 SLO 99% → エラーバジェット 1%(月間7時間のダウンタイムを許容)
- レイテンシー SLO 95% → エラーバジェット 5%(月間リクエストの内5%の遅延を許容)
バーンレート(Burn Rate)
エラーバジェットの消費速度。
バーンレート計算:
バーンレート = 現在のエラー率 / エラーバジェット
例:SLO 99%(月間エラーバジェット1%)のサービスで、1週間経過時点でエラー率が2%
バーンレートは以下の通り。
2% / 1% = 2
- このペースだと2週間でエラーバジェット枯渇(予定の2倍の消費速度)
- 残り3週間あるのに既に予算の半分を使用している危険な状態
この辺り少しややこしいのですが、要は常にエラー率1%であればエラーバジェットをちょうど消費し切るところを、1週間で切り取ってみると2%のエラーが発生しているため、予定の倍のエラーが発生している、ということが言いたいのです。
これが1日であっても1時間であっても考え方は同じで、エラーバジェットの何倍かを示すということが理解できれば良いかと思います。
概念についてはここまでで、続いては実際の進め方に移ります。
監視アラートチャンネルの整理
SLI/SLO を運用するということは、プロダクトの健全性を可視化し、もし SLO 違反になった場合は何らかの対応をするということになります。つまりは違反時に即座に検知する必要があります。
監視アラートチャンネルがあるとして、もしここが無法地帯になっていた場合、検知するのは困難です。そもそもそんな状態では SLI/SLO を運用しようとしても、他のアラートと同じように埋もれていつしか過去の遺産になりかねません。
そこでまずは、不要なアラートを削減していくことが大事になると考えました。以下のようなものを対象に、プロダクトチームと連携してアラートの見直しを図りました。
- 閾値が過剰でアラートが発報されてもいつも無視されているもの
→ 閾値の調整 - 夜間バッチ処理などで特定の時間帯は高負荷になることが分かっているもの
→ EventBridge Scheduler を使用し特定の時間帯のみアラートを無効化(先日アラームのミュート機能がリリースされましたね)
すごく単純ですが、これだけで相当数の無用なアラートを削減することができました。
かの有名なオライリーの『入門 監視』から得た学びを活かせた気がしました。
これで SLI/SLO を導入する最初の下準備はできたので、本題の SLI/SLO 設計を進めました。
SLI/SLO の設計
SLI/SLO は一人では設計できません。会社規模やプロダクト規模の目標値になるからです。私の場合はマネージャー陣に打ち出した上で、サーバーサイドの EM と SRE チームと共に進めることになりました。
認識合わせ
まずやったことは、なぜ導入するのか、改めて SLI/SLO とは何なのかという認識合わせです。 例えば導入のモチベーションについては以下のように(Gemini が)考えました。
なぜ今SLI/SLOが必要なのか
- サービスの安定性を数値で管理したい
- 開発速度と品質のバランスを適切に取りたい
- 障害対応の優先度を明確にしたい
- チーム間の共通認識を作りたい
現在の課題
- サービスレベルの判断が属人的・感覚的になっている
- 「安定している」「不安定」の基準が曖昧
- 開発を進めるべきか、品質改善を優先すべきかの判断が難しい
- 障害の影響度評価にバラツキがある
期待される効果
- 意思決定の高速化:数値ベースでの判断が可能
- リソース配分の最適化:開発 vs 運用の投資判断が明確に
- 組織全体の共通言語:エンジニアから経営層まで同じ指標で議論可能
SLI/SLO という単語自体には耳馴染みがあるものの、正確な言葉の定義や、結局どんなメリットがあるのか、ということを共通認識化しておくことは非常に重要だと思います。
SLI を決める
認識合わせができたところで、おそらく一番最初に決めるのは何を対象にするか、だと思います。
「我が社の SLI/SLO」という大きな単位で決めようとしても、複数プロダクト、複数 API がある場合は当然バラつきが出るため、意味のある数値にはなりません。そのため、「最注力している」「ユーザー影響が大きい」「売上が大きい」など、何か一つ基準を決めると良いと思います。
一般的には、CUJ(Critical User Journey) という 「ユーザーがサービス上で行うもっとも重要な操作の流れ」 を考えると良いとされています。例えば EC サイトであれば「トップページ → 商品ページの閲覧 → カートに入れる → 決済完了」の一連の流れなどが考えられます。
ただし今回は CUJ ベースではなくプロダクトベースで考え、最注力プロダクトを対象にしようということに決まりました。
ではこのプロダクトの何を測るかです。これがいわゆる SLI にあたります。
よくあるのが可用性とレイテンシーだと思いますのでこれを採用しました。(CUJ をしっかり検討された場合は、何を測れば良いのかはまた変わってくると思います)
このプロダクトは ALB, ECS, RDS を用いた構成だったので、ユーザーへの影響をそのまま表しているであろう ALB を対象にしました。
可用性 SLI の定義
特に言うことはありません。以下のようになりました。
- SLI: 成功リクエスト数 / 総リクエスト数 * 100
レイテンシー SLI の定義
可用性 SLI であれば上述のように何ともわかりやすい設定ができます。これは明確にリクエストを◯×で判定できるからです。
一方レイテンシーは秒数なので、単純に◯×では判定できません。目標値を設け、それを超えたかどうかで◯×判定する必要があります。
つまり、例えば以下のような設定になります。
- SLI: (レスポンスタイムが0.5秒以内のリクエスト数 / 総リクエスト数) * 100
- SLO: 95(%)
これは実は以下と全く同じです。
- SLI: p95のレスポンスタイム
- SLO: 0.5秒
こちらの方がシンプルに見えます。しかしこの場合、エラーバジェットが算出できないという問題があるのです。エラーバジェットは、どのくらい×判定のリクエストを許容するかを示す値です。あと何件の遅延が許容されるのかを示します。
これは「開発を進めるべきか、品質改善を優先すべきかの判断が難しい」というような課題解決に直結する大事なデータです。エラーバジェットに余裕があれば開発を優先し、エラーバジェットを下回っていたら開発を止めて回復に努めるといった判断材料になります。
もし SLI を「p95のレスポンスタイム」、SLO を「0.5秒」とした場合、「p95のレスポンスタイム」が仮に0.1秒だったとして、では一体どのくらいのリクエストの遅延が許容されるのか判断できません。なのでレイテンシー SLI は 「レスポンスタイムが0.5秒以内のリクエスト数」 としています。
Athena で API ごとに測定する
SLI の定義はできましたが、多数の API を持つ ALB(バックエンドの ECS) を対象にしていても、結局先の話の通り単位が大きいままです。API によってリクエスト数、エラー率、レイテンシーはまるで異なるので、同じ指標で測定してもまだ意味のある数値とは言えそうにありません。そこで、更に重要な API だけに絞って測定することにしました。
しかし、今度はこうなってくると単純な CloudWatch のメトリクスでは測定できません。API ごとの数値が出せないからです。そのため、 ALB のアクセスログを Athena を使用して測定することにしました。
この時、レイテンシーについては以下のフィルターを導入しました。
elb_status_code,target_status_codeが200~299の成功リクエストに限定したもの
これは、例えば一部のタイムアウトエラーによってレイテンシーが増加傾向に引っ張られたり、逆に即座にエラーが返された場合はレイテンシーが減少します。そのため、エラーに左右されずアプリケーション本来のレイテンシーを分けて測定したい場合に必要だと考えたためです。
尚、これとは別にエラーも含めた全リクエストのレイテンシーも測定しています。
特に「即座にエラーが返された場合はレイテンシーが減少する」という点については、 Watermelon Effect という、観測者側からは正常(Green)に見えているが、ユーザーから見ると異常(Red)が発生しているという状態に繋がりかねません。(その場合は可用性 SLO に現れるはずですが)
SLO を決める
SLI とフィルター条件が決まったので、具体的に目標値を決めていきます。これに関しては正解はありませんし、常々調整していくものだと思います。なので、まず現状を把握した上で妥当な値を決めてみて、あとは運用しながら調整することにしました。
ただし、可用性はそれを構成する各コンポーネントの可用性に依存します。自社サービスの SLO は、依存している全てのサービスの SLA を掛け合わせた値を上回ることはできません。
例えば AWS が SLA を99.9%としているのに、自社サービスの SLO を99.99%にはできないということです。
今回の対象プロダクトは以下の構成でしたので、それぞれの SLA を掛け合わせた数値が上限値になります。
Route 53 + ALB + ECS + RDS(全てMulti-AZ構成)
それぞれの SLA は以下の通りです。
- Route 53: 99.99%
- ALB: 99.99%(Multi-AZ)
- ECS on Fargate: 99.99%(Multi-AZ)
- RDS: 99.95%(Multi-AZ)
Route53
https://d1.awsstatic.com/legal/route53-sla/Amazon%20Route%2053%20SLA_Japanese_08.29.2022.pdf
ALB
Amazon Elastic Load Balancing Service Level Agreement
RDS
Amazon RDS SLA
これらを掛け合わせると以下の通りです。
99.99% * 99.99% * 99.99% * 99.95% = 99.92%
上限値がわかったところで、ざっと本サービスの過去実績も見てみたところ、可用性が恒常的に 99.9% を下回るということはなかったため、ほぼ上限値いっぱいですが SLO は「99.9%」としました。一方レイテンシーは可用性と同じように SLO の上限値を判断することはできませんが、同じく過去実績を見て「95%」で設定しました。
尚、厳密に言えば他にも使用しているサービスはありますが、まずは確実にユーザー体験に影響する主要サービスだけに限定して SLO 上限値を計算しました。仮に SLO 上限値を判断する上で考慮すべき依存サービスが漏れているとしても、それはあくまで SLO を 厳しく 設定しているということになるので、頻繁に SLO 違反になってしまう、ということがなければこのままでも問題ないと思います。
バーンレートアラーム
SLI/SLO の設計ができたところで、あとは Lambda などで日次で月間の累積値を Slack に通知したり、SLO 違反時に通知したりすれば何となく良さそうです。弊社ではこのような内容で毎朝 Slack に通知しています。

ただし、当初の目的はプロダクトの健全性を測ることであり、SLO 違反かどうかの◯×判定だけできれば良いわけではありません。
もちろん毎日通知されればなんとなくのトレンドは分かりますが、もし短期間で急激に悪化しても、月間の累積値で均されたら SLO 違反にはならず埋もれてしまうかもしれません。そしてある日突然 SLO 違反の通知が来てしまう、なんてことになりかねません。
つまり、ただ閾値ベースで監視していると、「緩やかな劣化」 に気付けないのです。 そこでバーンレートアラームが必要になります。この辺りは以下の記事に書かれている通りです。
バーンレートについては Google SRE の考え方を参考にしています。
ここで提唱されている閾値は以下の通りで、これをほぼそのまま採用しました。
| Severity | Long window | Short window | Burn rate | Error budget consumed |
|---|---|---|---|---|
| Page | 1 hour | 5 minutes | 14.4 | 2% |
| Page | 6 hours | 30 minutes | 6 | 5% |
| Ticket | 3 days | 6 hours | 1 | 10% |
表の意味としては、例えば1時間のタイムウィンドウで見た場合、バーンレートが14.4を超えた場合にアラートを発報し、これは月間のエラーバジェットの2%を消費しているということを意味します。
例:
- SLO: 99.9%
- 月間リクエスト: 1,000,000件
- エラーバジェット: 1,000,000件 × 0.1% = 1,000件/月のエラーを許容
平均的に均した時の消費速度は以下の通りです。
- 1,000件 / (30日×24時間) = 1.39件/時間 のエラーを許容
ではバーンレートが14.4の状態というのは、これの14.4倍のスピードでエラーが発生しているということになるため、
- 1.39件 * 14.4 = 20.016/時間
つまり1時間あたり約20件のエラー発生となり、月間のエラーバジェット1000件のうち20件の消費なので、 Error budget consumed が2%ということになります。
尚、3日で10%というのは、単純計算すると30日で100%なのでエラーバジェットが枯渇することはないペースですが、全て消費するペースではあるため何らかの対策が必要という状態を指します。
ちなみに「エラー」という言葉に引っ張られてどうしても可用性のみで考えてしまいがちですが、レイテンシーも◯×で判定できるようにしたので、×判定のリクエスト(閾値設定した秒数を超えている)は「エラー」扱いになります。
そしてこのようなバーンレートの判定を、 Short window 列のサイクルで回しています。
1時間のタイムウィンドウにおけるバーンレートは5分ごとに、6時間のバーンレートは30分ごと、3日間のバーンレートは6時間ごと、という感じです。
こうすることで、「一気にエラーが跳ねることはないが徐々に増えている」という、いわゆる 「緩やかな劣化」 にも気づけるようになりました。
あとは、以下のようなダッシュボードを作成して週1回の定例会で各 API の健全性を評価する場を設けることにしました。 ここに載せたものは全体が見られるシートですが、これとは別で複数のシートがあるように、個別の指標についてもそれぞれ用意しています。
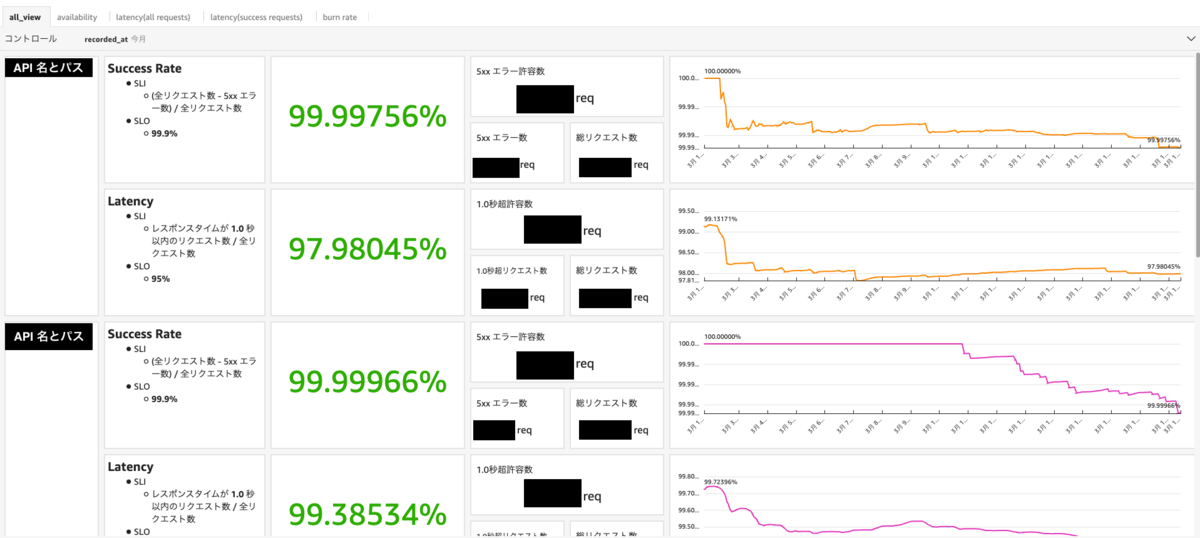
ダッシュボードは AWS の Quick Sight と S3 Tables を使用して構築しましたが、今回は具体的な構成については割愛させていただきます。
まとめ
以上が SLI/SLO 導入までの道のりでした。手探り状態から他社様の事例などを色々と参考にさせていただきながら始まった PJ ですが、日々目の前のタスクにばかり目が向きがちなところを、プロダクトに向き合って議論するのはとても良い機会でした。
まだ運用を始めたばかりのため、色々と見直すべきポイントは多分出てくるのだと思いますが、これから徐々にアップデートしていこうと思います。
ユニファでは家族の幸せを生み出すあたらしい社会インフラを一緒につくっていく仲間を大募集しています! 気になる方はぜひこちらのサイトもチェックしてみてください!!