こんにちは、rightgo09 です。今回は SaaS の Prerender を Amazon CloudFront で使うときの内容を記載します。
Prerender
目次
- Prerender
- Prerender とは
- Amazon CloudFront で使用する
- Amazon CloudFront のキャッシュキー
- CloudFront Functions
- Lambda@Edge
- CloudFront のまとめ
- Prerender のベストプラクティス
- Prerender 自体もキャッシュを持つ
- Prerender を使うデメリット
- まとめ
Prerender とは
SPA で Web サイトを構築すると、Google などのクローラ bot がすべてを解釈できずに適切なインデックスをしてくれないことがあります。その際の対応としては SSR(サーバサイドレンダリング)が有効ですが、工数の関係などで対応が難しい場合もあります。そのような問題を解決してくれるのが Prerender です。
Prerender は一言で言うと「レンダリングした結果の HTML を返してくれるサービス」です。SSR の外注とも言えるかもしれません。

使い方はシンプルで、事前にサイトから取得したトークンをヘッダに追加しつつ、レンダリングしてほしい URL を Prerender の API の URL にくっつけるだけです。
curl -H "X-Prerender-Token: <YOUR_PRERENDER_TOKEN>" https://service.prerender.io/https://www.example.com/
ちなみに、SaaS であると同時に OSS としても公開していて、自前でサービスを建てることもできるようです。
また、同様のサービスとしては他に Headless-Render-API などもあるようです。
Amazon CloudFront で使用する
Prerender はいくつかの導入方法を予め用意していますが、今回は Amazon CloudFront (CDN) を使用したパターンを確認します。
CloudFront はエッジコンピューティング機能を提供しており、超高速で簡素な CloudFront Functions と、もっとリッチな処理が可能な Lambda@Edge があります。これらを活用することで、本来 SSR が辛い環境でもクローラ bot にいい感じの結果を渡そうという構想です。
ちなみに、クローラ bot を判別して検索結果の上位に表示されるために通常とは異なる結果を返すことを「クローキング(Cloaking)」といい、Google はそれを違反とみなしていますが、今回の仕組みは見た目の内容が同じになるのでクローキングとはみなされません。
ref. クローキング | Google 検索セントラル | ドキュメント | Google Developers
今回のこの仕組みは、Google からは「ダイナミックレンダリング」と呼称されています。
ref. ダイナミック レンダリング | Google 検索セントラル | ドキュメント | Google Developers
※ 上記の URL 先にあるとおり、現在、ダイナミックレンダリングは根本的な解決策ではないので、ユーザ(とクローラ bot)が満足できる静的な HTML を分け隔てなく配る、というのがベストなのは間違いないようです。
Prerender のドキュメントに構築手法別の導入方法がいくつか載っており、こちらを参考にしています。
- ref. Available integrations - Integrations
- ref. GitHub - prerender/prerender-node: Express middleware for prerendering javascript-rendered pages on the fly for SEO
- ref. GitHub - jinty/prerender-cloudfront: prerender.io cloudfront example middleware
Amazon CloudFront のキャッシュキー
CloudFront の本来の目的はリクエストに対してキャッシュがあればそれを返す、いわゆるキャッシュサーバです。 デフォルトでは URL のパスとホスト名が保存のためのキー(キャッシュキー)となってキャッシュされています。 このデフォルトのキーを使用する場合、通常のユーザがアクセスした際に保存されたキャッシュをクローラ bot がアクセスした際にも使用されてしまうため、まずはこのキャッシュキーの対応をします。
通常のブラウザなどのアクセスとGoogle のクローラ bot のアクセスとで、最も区別可能な情報といえば、ユーザエージェントです。 しかし、単純にユーザエージェントをキャッシュのキーにすると、ユーザたちが使用しているブラウザは種類もバージョンも千差万別であるため、ブラウザに返したい内容(SPA 用の母体の HTML ページ)は全く同じなのに、ブラウザの数だけキャッシュが作られてしまうことになり、効率がよくありません(おそらく芳しくないキャッシュヒット率となる)。
CloudFront Functions
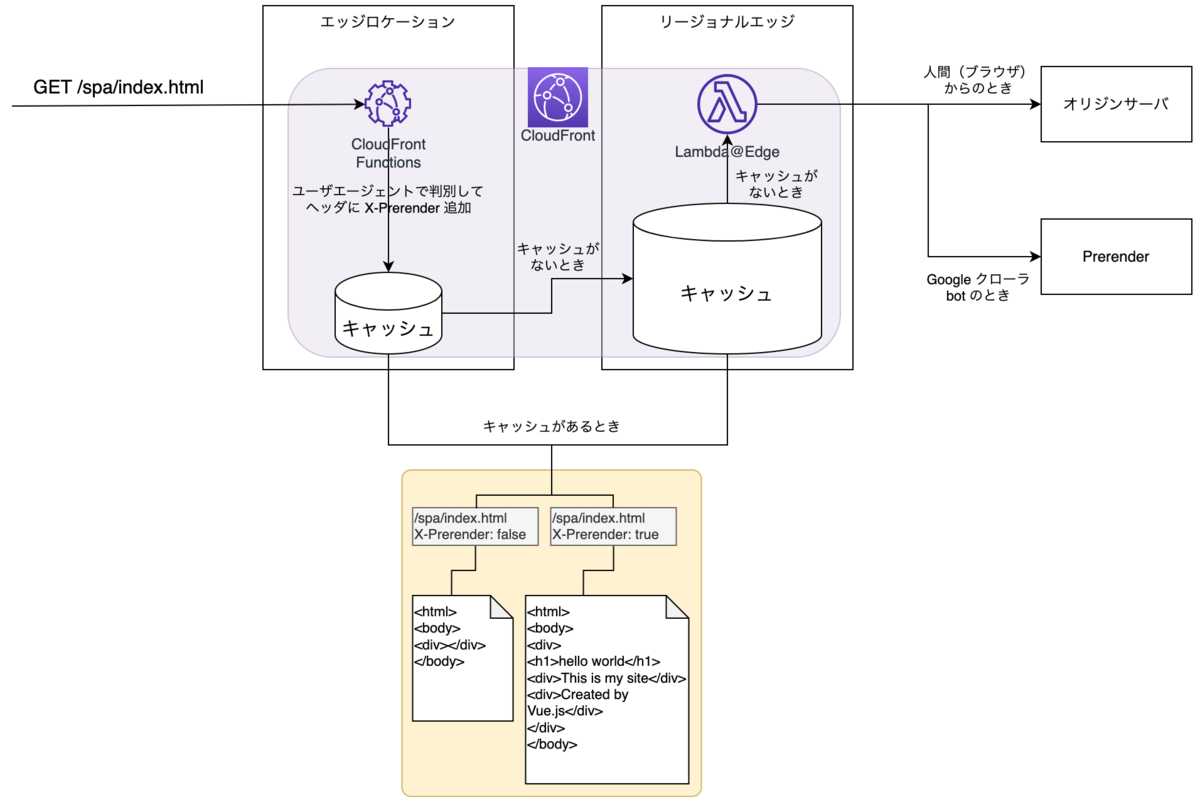
まずはアクセスが Google クローラ bot であるかどうかを判別して、「Prerender を使用するか否か」をキャッシュのキーにするという細工を施します。 具体的には、CloudFront Functions でキー役となる HTTP ヘッダを生成し、キャッシュポリシーでそれを拾います。
ref. CloudFront Functions の使い方を学ぶ - ユニファ開発者ブログ
CloudFront Functions のコード(ビューワリクエスト)
function handler(event) { var request = event.request; var headers = request.headers; var ua = headers["user-agent"]; var host = headers["host"]; if (ua && host) { var prerender = /googlebot/i.test(ua.value); // レンダリングと関係ないアクセスは対象にしない prerender = prerender && ! /\.(js|css|xml|less|png|jpg|jpeg|gif|pdf|doc|txt|ico|rss|zip|mp3|rar|exe|wmv|doc|avi|ppt|mpg|mpeg|tif|wav|mov|psd|ai|xls|mp4|m4a|swf|dat|dmg|iso|flv|m4v|torrent|ttf|woff|svg|eot)$/i.test(request.uri); if (prerender) { headers["x-prerender"] = { value: "true" }; } else { headers["x-prerender"] = { value: "false" }; } } return request; }
この X-Prerender ヘッダをキャッシュキーとなるように、CloudFront のキャッシュポリシーを新しく作成します。

これで、キャッシュキーは以下の組み合わせとなります。
- ホスト名
- URL パス
- X-Prerender とその値
ビヘイビアにこのキャッシュポリシーを設定することにより、同じ URL へのアクセスでも、Google クローラ bot かそうでないかで異なるキャッシュが保持されるようになりました。
キャッシュポリシーの TTL を短くすればするほど、Prerender へのアクセスが伝播する割合が高まるので要注意です。
Lambda@Edge
下準備は終わり、次に Lambda@Edge の処理を行っていきます。 Lambda@Edge は通常の Lambda と異なり、いくつか制限 があることに注意します。
今回の仕組みは、Lambda@Edge の動的オリジン選択の機能を利用します。 すなわち、CloudFront でオリジンとして設定したサーバではなく、そのアクセス先を捻じ曲げることができる、という仕様です。
全体構想としては以下のようになります。
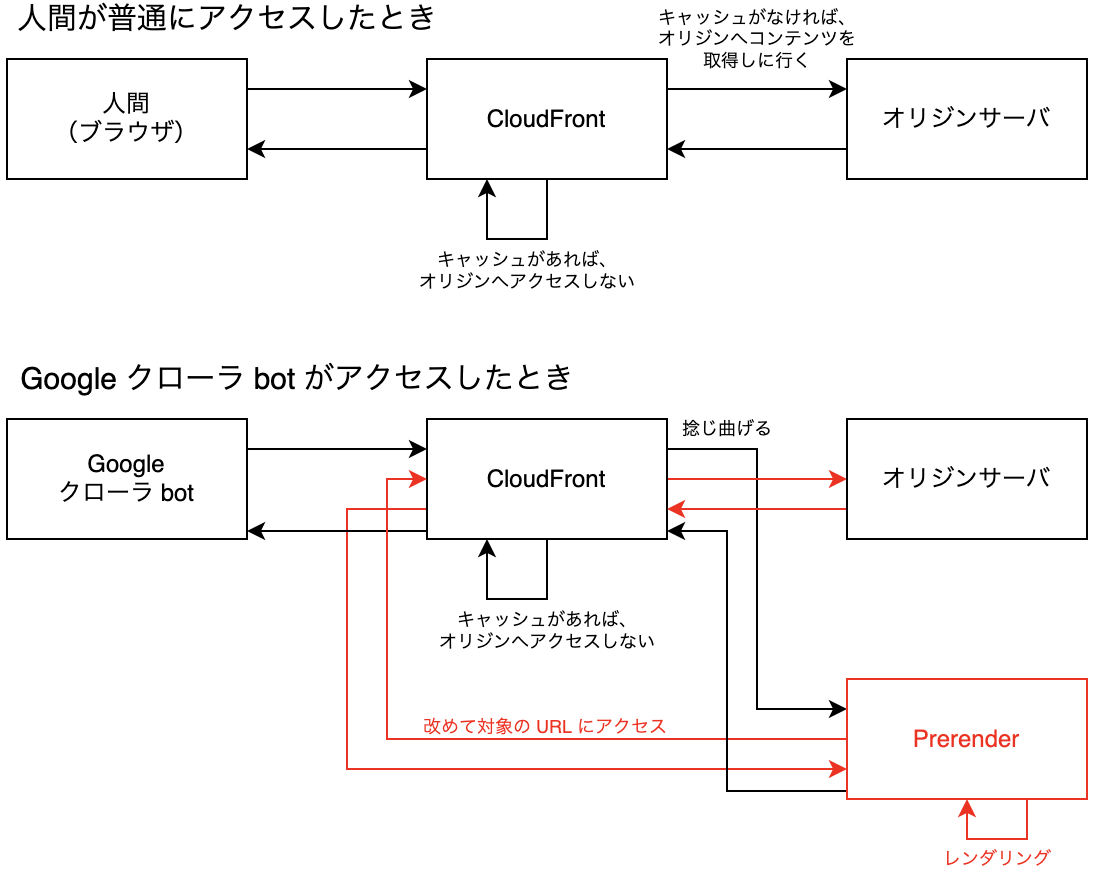
Lambda@Edge も CloudFront Functions と同じく、ビューワリクエストまたはオリジンリクエストに設置した場合、リクエストの構造を return すると、後続の処理へと伝播していきます(レスポンスの構造を return することも可能)。 後続とはすなわち、オリジンサーバへデータを取得しに行く処理です。
Lambda@Edge のコード(オリジンリクエスト)
exports.handler = (event, context, callback) => { const request = event.Records[0].cf.request; if (request.headers["x-prerender"][0].value === "true") { // ヘッダ追加(オリジンリクエストポリシーにも忘れずに!) request.headers["x-prerender-token"] = [ { "key": "X-Prerender-Token", "value": "XXXXXXXXXXX" }, // 直書き。環境変数は使用不可。 ]; request.origin = { custom: { domainName: "service.prerender.io", path: "/https%3A%2F%2Fxxxxxxxxxx.cloudfront.net" // request.headers["host"][0].value にはオリジンのホストが設定されていて使えないので注意 port: 443, protocol: "https", readTimeout: 20, keepaliveTimeout: 5, sslProtocols: ["TLSv1", "TLSv1.1", "TLSv1.2"], } }; } callback(null, request); };
request.origin の中身を書き換えることによって、オリジンサーバの向き先を Prerender に捻じ曲げ、あたかも SSR された結果をレスポンスとして伝播させることができるという寸法です(実際には SSR ではなく Prerender から実際にクライアントサイドでレンダリングした結果をもらっている)。
注意点として、Prerender へのアクセスの際には HTTP ヘッダに X-Prerender-Token の追加が必要となりますが、CloudFront の仕様として、Lambda@Edge でいくらヘッダを追加しても、それだけでは後続に伝播せず、捨てられてしまいます。
オリジンリクエストポリシーを新規作成し、X-Prerender-Token を許可した上で、ビヘイビアへの設定が必要となります。

CloudFront のまとめ
CloudFront 内での動きは以下のようになります。
Prerender のベストプラクティス
「レンダリング完了」というタイミングは Prerender 側からは完全には把握できないため、いくらかの遅延の後レンダリング完了しただろうという見込みの上で Prerender は HTML を返してくれているとのことです。
より詳細にこちらから完了を教えてあげる手立てとして、 window.prerenderReady プロバティの活用があります。
HTML の上部にて、
<script> window.prerenderReady = false; </script>
と忍ばせておき、自らが行っているレンダリングの最後の部分で、
window.prerenderReady = true;
とすると、それを足がかりに Prerender はレンダリング完了とみなしてくれるため、できれば採用すべきマーカかと思われます。
Prerender 自体もキャッシュを持つ
Prerender 側にもキャッシュ機構を備えており、同一の URL に対してキャッシュ保持期限内であれば、URL からリソースたちを取得してレンダリングして、という手順を踏まずに手持ちの HTML を返してくれます。デフォルトではキャッシュ保持は 7 日間となっていますが、設定で変更可能です。
また、定期的にキャッシュを再生成、すなわち、URL に自動的にアクセスしてレンダリング結果を保持し直す、ということも設定により可能です。
Prerender を使うデメリット
Prerender を使うデメリットですが、どこのキャッシュにも引っかからない場合の、HTML が返ってくる速度が圧倒的に遅いです。
今回の構成では、特に、アクセスが 2 周以上する + レンダリングする時間で、どんなに簡素な SPA でも全体で 5 秒近くかかってしまい、今度はこのレスポンス速度が Google クローラ bot の機嫌を損なうことになってしまいます。
新しいページを公開したとき、あるいはページの更新をしたときには、Google クローラ bot のユーザエージェントを掲げた自前の擬態アクセスによっていずれかのキャッシュに乗せるようにする、などの工夫が必要になるかもしれません。
まとめ
Prerender というサービスがなぜ存在し、どのように有効なのか、どのように組み込むことができるのかを学びました。今回は記載しませんでしたが、CloudFront が行っていることを、例えば Rails アプリの中に簡単に組み込むことも可能なようです。全体の仕組みがわかると、別の手段をとるとしたときにも、おそらくこのような機構だろうな、とあたりをつけやすくなると思うので、知るというのはアドであると、そう思いました。