こんにちは、プロダクトエンジニアリング部のちょうです。先月まだ残暑なのに、今月はダウンを取り出すほど冬っぽい気温になったんですね。みなさんも体調管理を気をつけて風邪にならないに注意してください。さて、普段Web開発ばかりやっているエンジニアとして、たまに他の分野をみて勉強してスキルを落ちないようにしていますが、身近のツールがどうやって動いているのも気になっています。
すこし前にTerraformとCloudFormationというIaC(Infrastructure as Code)ツールを触ることがありまして、2つのツールの共通点は依頼関係のあるリソースを並列で作成したり更新したりできます。そしてCloudFormationは一個のリソースが失敗したら、いままで実行した内容をロールバックすることができます。とても高度な機能のようなんですが、機能をシンプルにして、私達でも実装できるかを考えみましょう。
例えば、新規作成のみを考えて、AWS ECS Serviceを作成しましょう。
- CloudWatch LogGroup
- IAM Role
- ECS TaskDefinition (CloudWatch LogGroup, IAM Role)
- LoadBalancer
- LoadBalancer TargetGroup (LoadBalancer)
- LoadBalancer Listener (LoadBalancer, LoadBalancer TargetGroup)
- EC2 Security Group
- ECS Cluster
- ECS Service (ECS TaskDefinition, ECS Cluster, LoadBalancer Listener, LoadBalancer TargetGroup, EC2 Security Group)
一個のECS Serviceを作成するのに、関連するリソースがこんなに多いと思うかもしれませんが、注目してほしいのは、リソースととなり括弧の中にあるそのリソースが依頼しているほかのリソースです。すべてのリソースを作成するには、どんな作成順が期待されますかというと
まず、依頼するリソースがない
- CloudWatch LogGroup
- IAM Role
- Load Balancer
- ECS Security Group
- ECS Cluster
そして、作成したリソースを基づいてほかのリソース、例えばCloudWatch LogGroupとIAM Roleが終わればECS TaskDefinitionを作成できます。ような、こんな図になります。
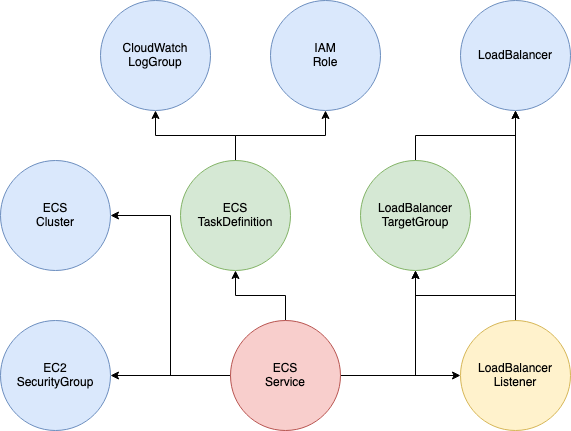
図の中で背景は水色のリソースは最初から作れます。そして並列処理します。背景は水色ではないリソースはほかのリソースの作成を待たないといけないです。つまり、依頼関係があるので、順番で処理しないとけないです。
ここまでまとめてみると、
- 並列処理
- 依頼関係を基づいて処理する
という機能要件があります。ほかに、もしデータ構造でグラフ(graph)を勉強したことがあるなら、これら有向グラフということがわかります。ただ、ここでデータ構造や理論を展開するつもりがありません。一つ有向グラフから気につけたいのはサイクルです。例えば、リソースAがリソースBを依頼して、リソースBもリソースAを依頼する場合、その依頼関係がサイクルになって、どちらも作成できなくなります。この問題を防ぐためにサイクルの検出も要件の一つになります。基本機能はこの3つの要件で十分です。エラーになるパターンやCloudFormationのロールバックは基本機能が終わってから考えましょう。
ゼロから作るには、おそらく並列処理の要件に気になります。最初に実行するリソースをわかってもそのあとはどうするかはわかりません。その場合一つの方法は並列処理がいらない処理を見つけ出します。例えば、サイクルの検出です。これは並列処理がいらなくてもいいです。実行する前に実行可能かをチェックするプログラムだからです。依頼関係を基づいて処理するのは処理形態は一番かかわるので、並列処理を切り離すことができません。ただ考えてみれば、最悪前の実行が終わったら、処理を制御するスケジューラーに一個大きなロックをかけて、次処理できるリソースを探します。なので、深く考えなくてもいいです。
TerraformがGolangで書かれて、並列処理に優れていてからできると思う人がいるかもしれません。実際Golangの並列制御の手段がすくない、特段ほかの言語よりやり方がかわりません。そしてGolangでつかいやすいと言われるcoroutineは依頼関係を基づいて処理する部分は使えません。要件は実際処理を制御するスケジューラーを作ります。既存のcoroutineのスケジューラーが似ているかもですが、そもそも改造できません。なので、本当にゼロから自分のスケジューラーを作ります。
依頼関係を基づいて処理するのは主に2つのポイントがあります。一つは最初に実行するリソースを探して、もう一つはほかのリソースが作成したら次に実行するリソースを探します。前者は簡単です。依頼のないリソースです。後者はすこしわかりにくいですが、依頼のあるリソースはほかのリソースが実行し終わったら自分の依頼リストにそのリソースを削除して、そのあともし依頼リストに何もないなら、このリソースが実行可能なリソースになります。これは再帰という考えです。

例えば、CloudWatch LogGroupとIAM Roleが終わったら、ECS TaskDefinitionの依頼リストすべてが実行済みになり、ECS TaskDefinitionが実行可能な水色になります。またLoadBalancerが作成済みになったら、LoadBalancer TargetGroupが実行可能になり、ただLoadBalancer ListenerはまだLoadBalancer TargetGroupを待っています。
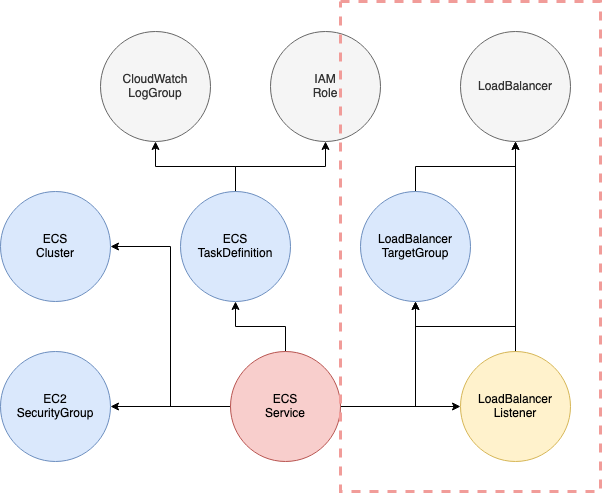
これで一番重要な順番に基づいて処理する部分がわかったと思います。もうひとつ重要なのはサイクルの検出です。サイクルの検出はDFSを基づいたアルゴリズムなどがあります。ただここではトポロジカルソート(topological sort)を使いたいです。トポロジカルソートはサイクルのない有向グラフのノードをソートするアルゴリズムで、サイクルがあるとソートできないです。そして、生成したリストはそのまま依頼関係を保ちながら順番で処理できます。並列処理で難しいでしたら、生成したリストをそのまま処理しても可能です。もちろん、並列処理になったら生成したリストは使えません。アルゴリズム自体はここで紹介しないですが、興味のある方はこちらのリンクを参照してください。
では、大体そろいました。実際のコードや実行はどうなりますでしょうか。
public static void main(String[] args) throws InterruptedException { ResourceBuilder builder = new ResourceBuilder(); List<Resource> resources = builder .add("CloudWatch LogGroup") .add("IAM Role") .add("ECS TaskDefinition", Arrays.asList("CloudWatch LogGroup", "IAM Role")) .add("LoadBalancer") .add("LoadBalancer TargetGroup", Collections.singletonList("LoadBalancer")) .add("LoadBalancer Listener", Arrays.asList("LoadBalancer", "LoadBalancer TargetGroup")) .add("EC2 Security Group") .add("ECS Cluster") .add("ECS Service", Arrays.asList("ECS TaskDefinition", "ECS Cluster", "LoadBalancer Listener", "LoadBalancer TargetGroup", "EC2 Security Group")) .build(); if (hasCycle(resources)) { throw new IllegalArgumentException("found cycle"); } DependentResourceParallelRunner runner = new DependentResourceParallelRunner(resources); runner.perform(); runner.await(); runner.stop(); }
コードはまず依頼関係のあるリソースを入力します。スケジューラーにフォーカスするため、名前と依頼関係だけで作ります。リソースを作成するとき、時刻と名前だけが出力されます。実際のリソースモデルです。
static class Resource { final String name; final Set<String> dependencies; final Set<String> referencedBy = new HashSet<>(); Resource(String name, Set<String> dependencies) { this.name = name; this.dependencies = dependencies; } void addReference(String name) { referencedBy.add(name); } boolean isNoDependency() { return dependencies.isEmpty(); } @Override public String toString() { return "Resource{" + "name='" + name + '\'' + ", dependencies=" + dependencies + ", referencedBy=" + referencedBy + '}'; } }
名前、依頼するリソースの名前セットと依頼されるリソースの名前セットです。依頼されるリソースの名前セットはサイクルチェックやスケジューラーで使われています。そして依頼関係で計算できます。下のResourceBuilderのbuildを注目してください。
static class ResourceBuilder { private final Map<String, Resource> resourceMap = new HashMap<>(); ResourceBuilder add(String name) { return add(name, Collections.emptyList()); } ResourceBuilder add(String name, List<String> dependencies) { if (resourceMap.containsKey(name)) { throw new IllegalStateException("resource with name " + name + " already exists"); } resourceMap.put(name, new Resource(name, new HashSet<>(dependencies))); return this; } List<Resource> build() { List<Resource> resources = new ArrayList<>(); for (Resource resource : resourceMap.values()) { for (String dependencyName : resource.dependencies) { Resource dependency = resourceMap.get(dependencyName); if (dependency == null) { throw new IllegalStateException("unknown dependency " + dependencyName + " in resource " + resource.name); } dependency.addReference(resource.name); } resources.add(resource); } return resources; } }
サイクルのチェックはトポロジカルソートを使いますので、依頼のないリソースとそれ以外のリソースを分類して、依頼のないリソースがないならサイクルがあると判定し、逆にその以外のリソースがないならサイクルがないと判定します。
static boolean hasCycle(Collection<Resource> resources) { List<Resource> resourcesWithoutDependencies = new ArrayList<>(); Map<String, ResourceReferenceCounter> remaining = new HashMap<>(); for (Resource resource : resources) { if (resource.isNoDependency()) { resourcesWithoutDependencies.add(resource); } else { remaining.put(resource.name, new ResourceReferenceCounter(resource)); } } return hasCycle(resourcesWithoutDependencies, remaining); } static boolean hasCycle(List<Resource> resourcesWithoutDependencies, Map<String, ResourceReferenceCounter> remaining) { // それ以外のリソースがないならサイクルなし if (remaining.isEmpty()) { return false; } // 依頼のないリソースがないならサイクルある if (resourcesWithoutDependencies.isEmpty()) { return true; } List<Resource> resourcesWithoutDependencies2 = new ArrayList<>(); for (Resource resource : resourcesWithoutDependencies) { for (String referenceName : resource.referencedBy) { ResourceReferenceCounter rc = remaining.get(referenceName); if (rc == null) { throw new IllegalStateException("reference " + referenceName + " not found"); } if (rc.remove(resource.name)) { remaining.remove(referenceName); resourcesWithoutDependencies2.add(rc.resource); } } } return hasCycle(resourcesWithoutDependencies2, remaining); } // 検出に利用するクラス static class ResourceReferenceCounter { final Resource resource; private final Set<String> dependencies; ResourceReferenceCounter(Resource resource) { this.resource = resource; this.dependencies = new HashSet<>(resource.dependencies); } boolean remove(String name) { if (!dependencies.remove(name)) { throw new IllegalStateException("resource " + resource.name + " is dependent on " + name); } return dependencies.isEmpty(); } }
スケジューラーは並列処理を対応するため、一つ大きかロックより各リソースにロックをかけて、集中しないように工夫しました。
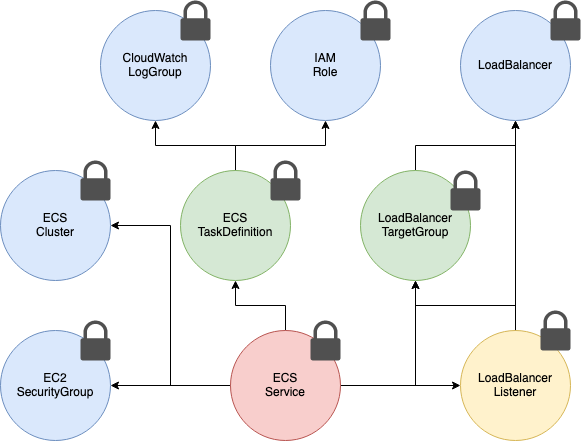
リソースが実行するときリソースより状態などいろんなものがあり、リソースの固定情報と別に実行用のモデルがあります。そして、リソースで名前のみで依頼関係を保持するより、実行用のモデルでは、関連モデルのインスタンスを直接アクセスできます。
static class ResourceCommand implements Runnable { private final Resource resource; private final Set<String> waiting; private final List<ResourceCommand> waitedBy = new ArrayList<>(); private final ResourceRunner runner; ResourceCommand(Resource resource, ResourceRunner runner) { this.resource = resource; this.waiting = new HashSet<>(resource.dependencies); this.runner = runner; } String resourceName() { return resource.name; } int addReferences(Map<String, ResourceCommand> resourceCommandMap) { for (String reference : resource.referencedBy) { ResourceCommand command = resourceCommandMap.get(reference); if (command == null) { throw new IllegalStateException("resource command " + reference + " not found"); } waitedBy.add(command); } return resource.referencedBy.size(); } @Override public void run() { DateFormat format = new SimpleDateFormat("HH:mm:ss.SSS"); System.out.println(format.format(new Date()) + " " + resource.name); try { Thread.sleep(1000L); } catch (InterruptedException ignored) { } if (waitedBy.isEmpty()) { runner.chainFinished(resource.name); } else { for (ResourceCommand command : waitedBy) { command.onResourceOk(resource.name); } } } void onResourceOk(String name) { synchronized (this) { if (!waiting.remove(name)) { throw new IllegalStateException("unexpected resource " + name); } if (waiting.isEmpty()) { runner.submitCommand(this); } } } } interface ResourceRunner { void submitCommand(ResourceCommand command); void chainFinished(String name); }
run
実行用のモデルに対して一番重要なのは実行が終わったとき、自分を待つほかのリソースを続いて実行するには、依頼関係をベースに逆算したResourceのreferencesにあるリソースを直接アクセスして通知します。複数リソースをまつリソースが複数リソースから通知があるため、リソースレベルのロックを使って処理します。これは個別リソースの間の処理なので同時実行に影響がありません。
もし自分をまつリソースがないなら、スケジューラーでチェーンが終わったという状態になります。チェーンが依頼チェーンの意味です。チェーンの最後のリソースはだれから依頼されていない特徴があります。すべてのリソースが処理済みの状態はすべてのリソースを待つより、これらのリソースをまつだけでいいです。
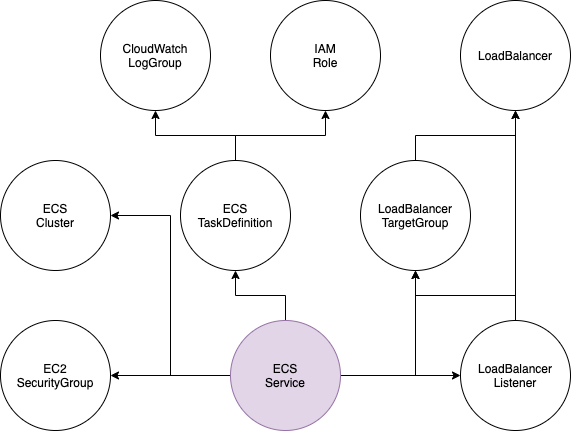
上の紫色のリソースはチェーンの最後のリソースなので、全体の処理スケジューラーはこの1つのリソースをまつのみになります。
onResourceOk
自分がまっているリソースができると通知され、自分がまっているリソースと比較して、もしもう待つリソースがないなら、実行可能になります。
最後はスケジューラーです。ロックを分散したおかげて、シンプルになっています。
static class DependentResourceParallelRunner implements ResourceRunner { private final List<Resource> resources; private final ExecutorService executorService; private Set<String> tailResourceNames; DependentResourceParallelRunner(List<Resource> resources) { this.resources = resources; this.executorService = Executors.newFixedThreadPool(8); } void perform() { List<ResourceCommand> resourcesWithoutDependencies = new ArrayList<>(); Map<String, ResourceCommand> resourceCommandMap = new HashMap<>(); tailResourceNames = new HashSet<>(); for (Resource resource : resources) { ResourceCommand command = new ResourceCommand(resource, this); if (resource.isNoDependency()) { resourcesWithoutDependencies.add(command); } resourceCommandMap.put(resource.name, command); } for (ResourceCommand command : resourceCommandMap.values()) { if (command.addReferences(resourceCommandMap) == 0) { tailResourceNames.add(command.resourceName()); } } for (ResourceCommand command : resourcesWithoutDependencies) { executorService.submit(command); } } @Override public void submitCommand(ResourceCommand command) { executorService.submit(command); } @Override public void chainFinished(String name) { synchronized (this) { if (!tailResourceNames.remove(name)) { throw new IllegalStateException("unexpected tail resource " + name); } if (tailResourceNames.isEmpty()) { tailResourceNames = null; notifyAll(); } } } void await() throws InterruptedException { synchronized (this) { if (tailResourceNames == null || tailResourceNames.isEmpty()) { return; } wait(); } } void stop() throws InterruptedException { executorService.shutdown(); executorService.awaitTermination(3, TimeUnit.SECONDS); } }
performはリソースを作成するメソッドで、最初は依頼のないリソースを作成します。そこからは各リソースにおまかせします。
実行するとこういう結果になります。
16:35:23.031 LoadBalancer 16:35:23.031 IAM Role 16:35:23.031 ECS Cluster 16:35:23.031 CloudWatch LogGroup 16:35:23.031 EC2 Security Group 16:35:24.056 LoadBalancer TargetGroup 16:35:24.056 ECS TaskDefinition 16:35:25.057 LoadBalancer Listener 16:35:26.060 ECS Service
結果はわかりやすいように、ブランクを入れています。期待された振る舞いの通りですね。
いかがでしょうか。依頼関係のあるリソースを並列で作成するのは難しそうに見えますが、実際基本機能をやったら300行もないですね。これをベースにエラーのパターンやロールバックを対応するバージョンを次回で説明したいので、それまでやり方を一緒に考えましょう。
以上です。最後までご覧いただきありがとうございました。
ユニファでは、最新のRubyを使ってアプリケーション開発したい人を募集しています。 気になる方は下記リンクから採用ページをご覧いただければと思います。