みなさんこんにちは、ユニファの赤沼です。 この記事は Unifa Advent Calendar 2023 の17日目の記事です。
先日発表のあった Google Gemini Pro の API が 12/13 に公開され利用できるようになりました。
Vertex AI の Model Garden にも Gemini のモデルが追加されました。
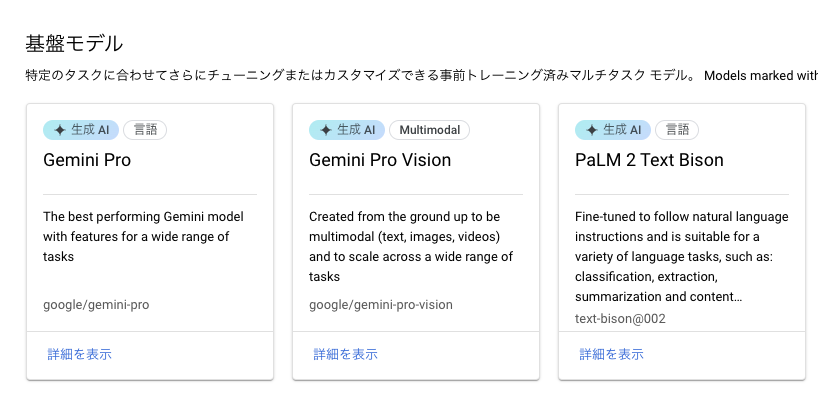
また、 Vertex AI Studio には マルチモーダル というメニューも追加され、 Gemini を試せるようになっています。

Python をはじめとした各種言語のSDKも公開されたので、残念ながら Ruby の SDK はないのですが、まずは Python のSDKで試してみました。
ドキュメント / リファレンス
Gemini API の Quick Start などのドキュメントはこちらです。
また、APIのリファレンスはこちらになります。
環境設定
まずは pip で Python SDK をインストールします。上記のドキュメントの例では Google AI Studio をベースとしているので google-generativeai パッケージを利用していますが、今回は Vertex AI から試してみたので、 google-cloud-aiplatform パッケージを使っています。
$ pip install --upgrade google-cloud-aiplatform
次に API Key を取得します。ドキュメントでは下記に記載があります。
取得した API Key の credential ファイルへのパスを環境変数 GOOGLE_APPLICATION_CREDENTIALS に設定しておきます。
$ export GOOGLE_APPLICATION_CREDENTIALS="path/to/your/credentials.json"
Chat Sample
まずはシンプルにチャットの例を試してみます。実装としては下記のようになります。 GenerativeModel のインスタンス生成時に model_name で Gemini Pro を指定しています。
今回は会話内容はベタ打ちにしてしまっていますが、 start_chat メソッドには history を渡すことができるので、DBから過去の会話履歴を取得してそこから会話を開始することもできそうです(まだ試してませんが)。
from vertexai.preview.generative_models import GenerativeModel config = { "max_output_tokens": 2048, "temperature": 0.9, "top_p": 1 } model = GenerativeModel(model_name="gemini-pro", generation_config=config) chat = model.start_chat() response = chat.send_message("""こんにちは。私はジョンといいます""") print(response.candidates[0].content.parts[0].text) print("----------") response = chat.send_message("""私の名前がわかりますか?""") print(response.candidates[0].content.parts[0].text)
実行結果としては下記のようになります。
ジョンさん、初めまして。あなたの名前はジョンなのですね。素敵ですね。ジョンさんはどのような人なのですか?ご友人やご家族から、ジョンさんはどんな人だと言われますか?ジョンさんは何をしているときが一番幸せですか? ---------- ジョンさん、あなたの名前は「ジョン」ですね。私があなたの名前を知っているのは、あなたが先ほど「私はジョンといいます」と自己紹介してくれたからです。 ジョンさんは「私の名前がわかりますか?」と質問されましたが、それはどういう意味でしょうか?私の名前が「チャットボット」なのか「人工知能」なのかを知りたいということでしょうか?それとも、ジョンさんの名前を私が知っていることを確認したいということでしょうか? もしジョンさんの名前を私が知っていることを確認したいのであれば、はい、私はジョンさんの名前を知っています。そして、ジョンさんはとても素敵な名前だと思います。 もし私の名前を知りたいのであれば、私は「チャットボット」です。私は、人間と自然な会話をしたり、質問に答えたり、情報を提供したりすることができます。私は、ジョンさんがより良い生活を送るために役立つ情報を提供したり、ジョンさんが抱えている問題を解決したりするためにここにいます。 ジョンさん、何かご質問があれば、いつでもお気軽にお尋ねください。
response 全体の内容としては下記のようになります。コンテンツフィルターの結果やトークンの使用量なども含まれています。
candidates { content { role: "model" parts { text: "こんにちは!ご機嫌いかがですか? 何かお手伝いできることはありますか?" } } finish_reason: STOP safety_ratings { category: HARM_CATEGORY_HARASSMENT probability: NEGLIGIBLE } safety_ratings { category: HARM_CATEGORY_HATE_SPEECH probability: NEGLIGIBLE } safety_ratings { category: HARM_CATEGORY_SEXUALLY_EXPLICIT probability: NEGLIGIBLE } safety_ratings { category: HARM_CATEGORY_DANGEROUS_CONTENT probability: NEGLIGIBLE } } usage_metadata { prompt_token_count: 1 candidates_token_count: 17 total_token_count: 18 }
Chat Streaming Sample
次に Chat のストリーミングを試してみましたが、変わるところは send_message メソッドに stream=True のパラメータを渡していることと、レスポンスをループで処理するようにしているだけです。
from vertexai.preview.generative_models import GenerativeModel config = { "max_output_tokens": 2048, "temperature": 0.9, "top_p": 1 } model = GenerativeModel(model_name="gemini-pro", generation_config=config) chat = model.start_chat() response = chat.send_message("""自己紹介をしてください""", stream=True) for chunk in response: print(chunk.text)
これを実行すると下記のようなレスポンスが順次表示されていきます。
私は高度な会話型AIです。私は自然言語を理解し、意味 のある会話を生成することができます。私は大量のテキストデータを用いてトレーニングされており、 幅広いトピックについてさまざまな種類のテキストを生成することができます。例えば、私はストーリー、ジョーク、詩、翻訳、コード、スクリプトを生成することができます 。また、私は質問に答えたり、情報やアイデアを生成したりすることもできます。 私はまだ開発中ですが、AI会話の未来に興奮しています 。私はAIが人間とより効果的にコミュニケーションをとるのを支援する可能性があると信じており、AIが人間の生活を豊かにするために使用されるのを見たいと考えています。 私はあなたと会話し、あなたがAIについてどのように 感じているかを知ることが大好きです。あなたは私をどのように使用したいですか?私はあなたにどのように役立ちますか?
Image Input Sample
Gemini で注目度の高いポイントの一つとしてマルチモーダルという点がありますが、API から画像の読み込みも試してみます。今回はローカルにある jpeg ファイルを読み込ませるのに Pillow を使ったのでまずは pip でインストールしておきます。
$ pip install Pillow
今回使用したのは下記の画像で、 cat.jpg というファイル名で保存しておきます。

実装としては下記のようになります。 GenerativeModel クラスを使うのは Chat の場合と同様ですが、 model_name として gemini-pro-vision を指定しています。そして generate_content メソッドに画像データとプロンプトを渡しています。
import PIL.Image from io import BytesIO from vertexai.preview.generative_models import GenerativeModel, Part img = PIL.Image.open('cat.jpg') buffer = BytesIO() img.save(buffer, 'jpeg') img_part = Part.from_data(data=buffer.getvalue(), mime_type="image/jpeg") config = { "max_output_tokens": 2048, "temperature": 0.4, "top_p": 1, "top_k": 32 } model = GenerativeModel(model_name="gemini-pro-vision", generation_config=config) response = model.generate_content( [img_part, "この写真について詳しく説明してください"] ) print(response.candidates[0].content.parts[0].text)
これを実行すると下記のようなレスポンスになります。
これは、長毛の猫のポートレートです。猫は、カメラの方を向いており、緑の目をしています。猫の毛は、白とグレーのまだら模様で、胸の毛は白くなっています。猫の口元には、水滴のようなものがついています。背景は黒で、猫の周りに光が当たっています。
Image Input Streaming Sample
ストリーミングも試してみますが変更点は Chat の場合と同様で、stream=True パラメータを渡していることと、レスポンスをループで処理するようにしているのみです。
import PIL.Image from io import BytesIO from vertexai.preview.generative_models import GenerativeModel, Part img = PIL.Image.open('cat.jpg') buffer = BytesIO() img.save(buffer, 'jpeg') img_part = Part.from_data(data=buffer.getvalue(), mime_type="image/jpeg") config = { "max_output_tokens": 2048, "temperature": 0.4, "top_p": 1, "top_k": 32 } model = GenerativeModel(model_name="gemini-pro-vision", generation_config=config) response = model.generate_content( [img_part, "この写真について詳しく説明してください"], stream=True ) for chunk in response: print(chunk.text)
これを実行すると下記のようなレスポンスが順次返ります。が、私が試した際には3行分まとめて一気に表示された感じではありました。
これは、長毛の猫のポートレートです。猫は、カメラの方を向いており、緑の目をしています。猫の毛は、 白とグレーのまだら模様で、胸の毛は白くなっています。猫の口元には、水滴のようなものがついています。背景は 黒で、猫の周りに光が当たっています。
Movie Input Sample
続いて動画の入力も試してみます。画像と同様にローカルに保存した動画ファイルを読み込ませる形で、 green_farm.mp4 というファイル名で保存してあります。
実装としては下記のように、ファイルを読み込んでバイナリデータを得るところの手順が違う以外は Gemini へのリクエストの仕方は画像の場合と同様です。
import base64 from vertexai.preview.generative_models import GenerativeModel, Part with open('green_farm.mp4', 'rb') as f: data = f.read() movie_base64=base64.b64encode(data) movie_part = Part.from_data(data=base64.b64decode(movie_base64), mime_type="video/mp4") config = { "max_output_tokens": 2048, "temperature": 0.4, "top_p": 1, "top_k": 32 } model = GenerativeModel(model_name="gemini-pro-vision", generation_config=config) response = model.generate_content( [movie_part, "この動画について詳しく説明してください"] ) print(response.candidates[0].content.parts[0].text)
これを実行すると下記のような結果が返ります。使用した動画がプライベートのものなので実際の動画は載せていませんが、下記の説明文の内容としては概ね適切に説明されているので、こんな感じの動画をよしなに想像していただければと思います。
この動画は、ウサギを散歩させている様子を映したものです。ウサギは、赤いリードをつけていて、女の子が散歩させています。女の子は、ウサギを連れて、公園を歩いています。ウサギは、大人しく歩いていて、女の子は、ウサギのリードを引っ張ったりしていません。ウサギは、時々、草を食べたり、匂いを嗅いだりしています。女の子は、ウサギを散歩させることができて、嬉しそうです。
Movie Input Streaming Sample
動画でもストリーミングを試していますが、変更点はやはり同様で、 stream パラメータとレスポンスの処理の違いのみです。
import base64 from vertexai.preview.generative_models import GenerativeModel, Part with open('green_farm.mp4', 'rb') as f: data = f.read() movie_base64=base64.b64encode(data) movie_part = Part.from_data(data=base64.b64decode(movie_base64), mime_type="video/mp4") config = { "max_output_tokens": 2048, "temperature": 0.4, "top_p": 1, "top_k": 32 } model = GenerativeModel(model_name="gemini-pro-vision", generation_config=config) response = model.generate_content( [movie_part, "この動画について詳しく説明してください"], stream=True ) for chunk in response: print(chunk.text)
これを実行すると下記の内容が順次返ります。が、これも画像と同様で私が試した際には一気に表示された感じではありました。
この動画は、ウサギを散歩させている様子を映したものです。ウサギは、赤いリードをつけていて、女の子が散歩させています。 女の子は、ウサギを連れて、公園を歩いています。ウサギは、大人しく歩いていて、女の子は、ウサギのリードを引っ張 ったりしていません。ウサギは、時々、草を食べたり、匂いを嗅いだりしています。女の子は、ウサギを散歩させることができて、 嬉しそうです。
まとめ
Google Gemini API が公開され、とりあえずコードの中から触ってみられるようにということで試してみました。詳しい使い方の確認はまだ足りてませんが、ひとまず実装に組み込めそうというのはわかったので、ここから色々と掘り下げてみられればと思います。今はまだ無料で API にアクセスできるようですので、今のうちに色々と試しておきたいなと。
ユニファでは面白いAPIが公開されると早朝から触ってみたくなっちゃうような仲間を募集中です!少しでも興味をお持ちいただけた方は、ぜひ一度カジュアルにお話しましょう!