こんにちは、データエンジニアリングチームの宮崎です。
少し今更ですが、最近SageMakerにオリジナルのTensorFlowモデルをデプロイできることを知ったので試してみました。 (これまでSageMakerで学習したモデルしかデプロイできないと思っていました…。)
モチベーション
以前、コチラの記事でAWS Lambda上にTensorFlowモデルのデプロイについてご紹介しました。 しかし、AWS Lambdaですとコールドスタート時は応答に20秒前後かかり、応答速度が求められるタスクには辛いところがあります。 また、常に多数のクライアントから推論リクエストがくるケースにも不向きです。 そういったケースはTensorFlow Servingが良さそうですが、ECSにデプロイしようとすると、ロードバランサなどの設定も必要で少々面倒です。
そこで今回は、マネージドでTensorFlow ServingをデプロイしてくれるSageMakerを用い、オリジナルのTensorFlowモデルをデプロイしてみました。
Saved Modelの出力
はじめにSaved Modelを出力します。
Saved Modelの作成にはコチラの記事の model_exporter.py を使用します。
$ python model_exporter.py --export_path imagenet-resnet50/1
カスタムハンドラの作成
次に、カスタムハンドラを作成します。 SageMakerのデフォルトハンドラはRESTで推論リクエストを送信するため、画像データをBase64エンコードする必要があります。 そしてTensorFlow Serving側は画像データを受け取るため、Saved ModelにBase64のデコード処理を予め組み込んでおく必要があります。
今回は既にモデルを作成済みのため、Saved Modelをそのまま利用できるgRPCのリクエスト送信をカスタムハンドラに実装したいと思います。 また、合わせてカスタムハンドラにはS3から画像を取得する処理も組み込みます。 これによって、クライアント側はS3キーを送るだけで、よしなに推論してくれるエンドポイントを作ることができます。 したがって全体の構成としては以下のようになります。
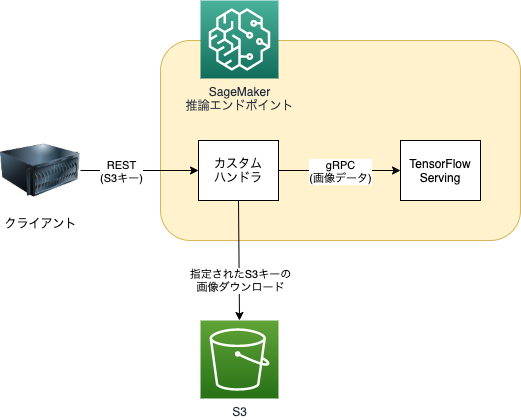
カスタムハンドラのコードは以下のようになります。
注意点として、カスタムハンドラの関数名は handler とする必要があります。
また、context.grpc_port にgRPCポートが設定されているため、これを使って送信先アドレスを作成します。
preprocess で入力されたS3キーから画像をダウンロードし、TensorFlow ServingにgRPCでリクエストを送信します。
そして受信したレスポンスを postprocess でJSONに変換し、クライアントに返します。
def handler(serialized_data, context) -> Tuple[str, str]: data = json.loads(serialized_data.read().decode('utf-8')) images = preprocess(data) server = f'localhost:{context.grpc_port}' with grpc.insecure_channel(server) as channel: stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) request = predict_pb2.PredictRequest() request.model_spec.name = 'imagenet-resnet50' request.model_spec.signature_name = 'serving_default' images_tensor_proto = make_tensor_proto(images) request.inputs['images'].CopyFrom(images_tensor_proto) response = stub.Predict(request, 20.0) return postprocess(response) def preprocess(data: dict) -> np.ndarray: s3_object = s3_client.get_object( Bucket=data['bucket'], Key=data['s3_key']) image_data = io.BytesIO(s3_object['Body'].read()) image = Image.open(image_data).convert('RGB') images = np.expand_dims(np.array(image), axis=0) return images def postprocess(data: predict_pb2.PredictResponse) -> Tuple[str, str]: result = {} for key, value in data.outputs.items(): if value.dtype == types_pb2.DT_FLOAT: val = np.array(value.float_val) elif value.dtype == types_pb2.DT_STRING: val = np.array(value.string_val).astype(str) else: continue result[key] = val.reshape( [dim.size for dim in value.tensor_shape.dim]).tolist() result['model_version'] = int(data.model_spec.version.value) response_content_type = 'application/json' return json.dumps(result), response_content_type
gRPCの利用にあたっては事前にgRPCライブラリをビルドしておきます。
TensorFlowパッケージを入れても良いのですが、エンドポイントデプロイ時の時間を短縮するため、自前でビルドしました。
また、ここで最新バージョンのgrpcio-toolsでビルドしてしまうと、SageMaker側とバージョンが合わずエラーになってしまうので、注意が必要です。
$ pip3 --no-cache-dir install grpcio==1.29.0 grpcio-tools==1.29.0
$ git clone --depth 1 -b v2.3.1 https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
$ python3 -m grpc_tools.protoc \
-I. \
--python_out=../code \
--grpc_python_out=../code \
tensorflow/core/{framework,example,protobuf}/*.proto
モデルファイルの作成およびアップロード
最終的にSageMakerにデプロイするモデルファイルは以下のようになります。
カスタムハンドラのコードは code ディレクトリ に格納する必要があります。
.
├── code
│ ├── inference.py # カスタムハンドラを記述したコード
│ ├── requirements.txt
│ └── tensorflow # gRPCライブラリ
│ └── core
│ ├── example
│ │ ├── example_parser_configuration_pb2.py
│ │ ├── ...
│ │ └── feature_pb2_grpc.py
│ ├── framework
│ │ ├── allocation_description_pb2.py
│ │ ├── ...
│ │ └── versions_pb2_grpc.py
│ └── protobuf
│ ├── autotuning_pb2.py
│ ├── ...
│ └── worker_service_pb2_grpc.py
└── imagenet-resnet50 # Saved Model
└── 1
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
Saved Modelおよびカスタムハンドラのコードを圧縮し、モデルファイルとしてS3にアップロードします。
$ tar cvfz model.tar.gz imagenet-resnet50 code $ aws s3 cp model.tar.gz s3://<bucket_name>/<dir_name>/
SageMakerエンドポイントのデプロイ
アップロードしたモデルファイルをSageMaker推論エンドポイントにデプロイします。 今回はSageMaker Python SDKを使用しました。
from sagemaker.tensorflow import TensorFlowModel model = TensorFlowModel( model_data='s3://<bucket_name>/<dir_name>/model.tar.gz', entry_point='inference.py', role='arn:aws:iam::<account>:role/<sagemaker_exec_role>', framework_version='2.3.1', name='imagenet-resnet50') model.deploy( initial_instance_count=1, instance_type='ml.t2.medium', endpoint_name='imagenet-resnet50')
推論リクエストの送信
デプロイが成功したら、推論リクエストを送信してみます。 今回もこちらの画像を使用しました。

import boto3 sagemaker_client = boto3.Session().client('sagemaker-runtime') response = sagemaker_client.invoke_endpoint( EndpointName='imagenet-resnet50', Body=json.dumps({ 'bucket': '<bucket_name>', 's3_key': 'elephant.jpg' }), ContentType='application/json' ) result = json.load(response['Body']) for label, confidence in zip( result['labels'][0], result['confidences'][0]): print(f'{label:<20}: {confidence:0.6f}')
推論結果です。ちゃんとインド象と推論してくれました。
Indian_elephant : 0.888790 tusker : 0.099783 African_elephant : 0.011377 water_buffalo : 0.000025 hippopotamus : 0.000006
まとめ
SageMakerにオリジナルのTensorFlowモデルをデプロイしました。 SageMakerはECSより若干インスタンス料金が増えますが、 ロードバランサを意識しなくてよくなるので便利です。 また、カスタムハンドラによって、前処理・後処理も柔軟に行うことができました。
一方で、カスタムハンドラ周りについては資料が少なく、ディレクトリ名や関数名が決まっているなど、少しとっつきづらかったです。 前後の処理を知りたい方はこちらのコードを参照すると、理解が深まるかと思います。 いずれにしても、無事にデプロイできたので、この先活用できればと思っています。
ソースコード
今回使用したソースコードです。
参考資料
- Deploying to TensorFlow Serving Endpoints — sagemaker 2.49.0 documentation
- GitHub - aws/sagemaker-python-sdk: A library for training and deploying machine learning models on Amazon SageMaker
- GitHub - aws/sagemaker-tensorflow-serving-container: A TensorFlow Serving solution for use in SageMaker.
ユニファで一緒に働く仲間を募集しています!