こんにちは、データエンジニアリングチームの宮崎です。
最近、ユニファのデータを統合的に分析するための基盤開発に取り組んでおります。 そこで、本記事では開発の概要についてご紹介したいと思います。
開発のモチベーション
これまで、ユニファでは日々のデータ分析にRedashを用い、直接サービス中のDBに対してクエリを投げて行ってきました。 しかし、サービスの成長とともにDBへの負荷が懸念されたり、複数のプロダクトやCRMのデータを組み合わせて統合的に分析したいという需要が高まってきました。 そこで、サービス中のDBから独立して実行可能で、よりリッチな分析を可能とするデータ分析基盤の開発に取り組み始めました。
データウェアハウスの選定
今回、データ分析基盤の中核となるデータウェアハウスとしてGCPのBigQueryを採用することにしました。 ユニファではメインのクラウドとしてAWSを活用しており、各サービスのデータも多くがAWSのDBに保存されております。 これらを同期させることを考えると同じAWSのAthenaやRedshiftが適していそうです。
一方で、AWSアカウントはエンジニアのみしか保持していないのに対し、ユニファではメールやオフィスツールなどの基盤としてGoogle Workspaceを使用しており、全社員がGoogleアカウントを保持しいます。 また、日常的に使用しているGoogleスプレッドシートがBigQueryと連携可能な点も魅力的です。 そのため、直近のデータ同期のしやすさよりも、今後の利用促進の利点を考え、BigQueryを採用することにしました。
データ同期方法の検討
さて、BigQueryでデータ分析を可能とするためには、AWSのデータをBigQueryに同期するための仕組みが必要です。 ユニファではサービスごとにAWSアカウントがあり、それぞれのRDSにデータを格納しております (参考: ユニファのシステムの移り変わり(後編) - ユニファ開発者ブログ)。
これらのデータ同期の方法として、少し検索してみるとEmbulkなどのOSS、TroccoなどのSaaSサービス、そしてGlueなどのAWS・GCPのサービスなど様々な選択肢があることがわかります。 これらの中から、ランニングコストやメンテナンスの工数を考え、GlueとBigQuery Data Transfer Serviceを利用することにしました。
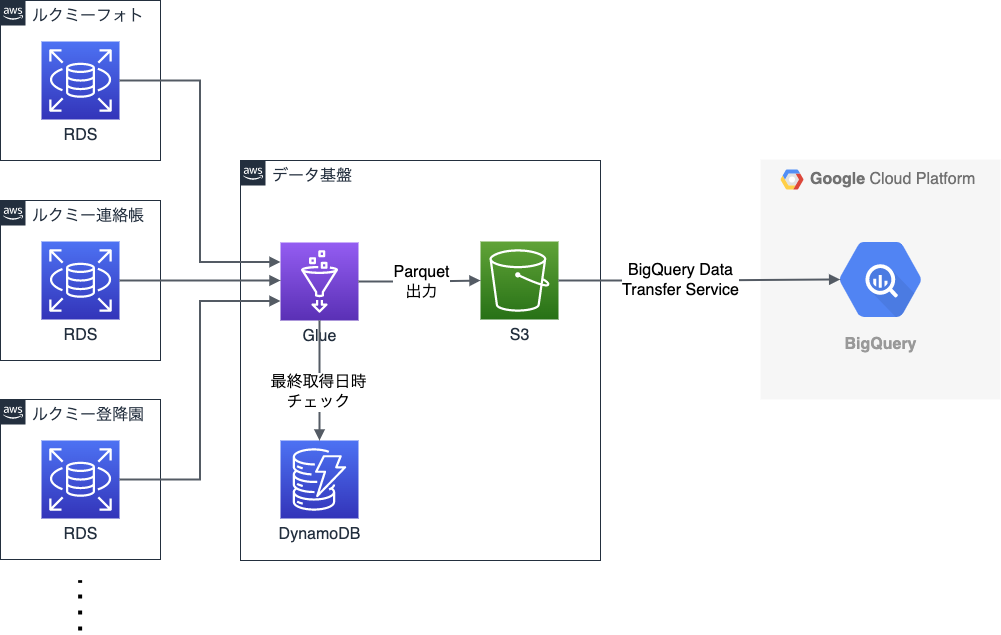
処理の流れは以下のようになっています。
- はじめにGlueを各RDSに接続します。(参考: AWS GlueからTransit Gatewayを経由して異なるアカウントのRDSに接続する - ユニファ開発者ブログ)
- 各RDSにSELECTクエリを発行し、得られたデータをParquetでS3に保存します。
- BigQuery Data Transfer ServiceでS3からBigQueryにParquetを読み込みます。
データの同期は日次で行っています。毎回全件取得を行うと大変なので、通常は前日からの更新分のみを対象とした差分取得を行っています。
幸いにもユニファではRuby on Railsで開発をしており、基本的にはどのテーブルにも updated_at カラムがあります。
そこで、updated_at カラムをチェックし、新しいレコードのみを取得することで差分取得を実現しています。
発想としてはGlueのブックマーク機能と同じですが、残念ながらGlueContextで処理すると遅かったため、SparkのSQLContextで処理し、ブックマーク機能をDynamoDBを利用して再現しています。
また、この差分取得の方法では物理削除に対応できないため、月次で全データの洗い替えを行うことで、削除の反映を行っています。
Glueジョブスクリプト
RDSからデータを取得し、Parquetを出力するためのGlueジョブスクリプトについて紹介したいと思います。 GlueジョブスクリプトはPythonで実装しました。 なお、以下のコードは簡単化のため、パラメータの読み込みや例外処理は省略しております。
まずはじめに、Glueジョブを初期化します。
import sys from pyspark.context import SparkContext from pyspark.sql import SQLContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.utils import getResolvedOptions sc = SparkContext() sqlContext = SQLContext(sc) glueContext = GlueContext(sc) logger = glueContext.get_logger() spark = glueContext.spark_session job = Job(glueContext) args = getResolvedOptions(sys.argv, ['JOB_NAME']) job.init(args['JOB_NAME'], args)
続いて、DBの接続情報を設定します。 GlueContextではなく、SQLContextを使用して接続するため、Glue Connectionを使えません。 そこで、別途DBの接続情報を取得する必要があります。 ここでは簡単化のため、直接スクリプトに書き込んでいますが、Glueジョブの引数で与えるとより利便性が高くなるかと思います。 なお、パスワードは安全のためSystem Managerのパラメータストアから取得しています。
import boto3 db_name = 'mydatabase' db_url = 'jdbc:postgresql://mydatabase.xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:5432/mydatabase' db_driver = 'org.postgresql.Driver' db_user = 'dbuser' table_name = 'mytable' ssm_client = boto3.client('ssm') response = ssm_client.get_parameter( Name='db_pass', WithDecryption=True ) db_password = response['Parameter']['Value']
DBの接続情報を得られたら、続いてデータの取得範囲を絞るため、
ブックマーク情報、すなわちupdated_at の値を取得します。
前回読み込み時の値はDynamoDBから取得し、最新の値はDBから取得します。
# 前回のブックマーク値 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('data-export-bookmarks') response = table.get_item( Key={'database_name': db_name, 'table_name': table_name}) prev_bookmark = response.get('Item').get('bookmark') # 今回のブックマーク値 bookmark_key = 'updated_at' t1 = f''' (SELECT max({bookmark_key}) FROM {table_name} WHERE {bookmark_key} > '{prev_bookmark}') as t1 ''' row = sqlContext.read.format('jdbc').options( url=db_url, driver=db_driver, user=db_user, password=db_password, dbtable=t1).load().first() curr_bookmark = row[0]
次に、SparkでDBからデータを読み込む際の並列数を定めます。
まず プライマリキーである id の最小値と最大値を取得し、現在のおおよその行数を取得します。
そして、1回あたりの読み込み行数を300,000行とし、取得対象の行数を割った値を読み込み時の並列数としています。
import math primary_key = 'id' t2 = f''' (SELECT max({primary_key}), min({primary_key}) FROM {table_name} WHERE {bookmark_key} > '{prev_bookmark}') as t2 ''' row = sqlContext.read.format('jdbc').options( url=db_url, driver=db_driver, user=db_user, password=db_password, dbtable=t2).load().first() upper_bound, lower_bound = row max_rows = 300000 num_parallel_reads = math.ceil((upper_bound - lower_bound) / max_rows)
いよいよデータを読み込みます。これまでに得られた境界値や並列数を設定して読み込んでいきます。 なお、こちらの並列読み込みについては AWS Glue で 億超えレコードなテーブルからETLする - Qiita をとても参考にさせていただきました!
t3 = f''' (SELECT * FROM {table_name} WHERE {bookmark_key} <= '{curr_bookmark}' AND {bookmark_key} > '{prev_bookmark}') as t3 ''' df = sqlContext.read.format('jdbc').options( url=db_url, driver=db_driver, user=db_user, password=db_password, dbtable=t3, numPartitions=num_parallel_reads, partitionColumn=primary_key, upperBound=upper_bound, lowerBound=lower_bound).load()
最後に、得られたデータをParquetで保存し、DynamoDBのブックマークを更新したらGlueジョブをコミットして完了です。
import time # Parquetを出力 output_path = f's3://mybucket/{db_name}/{table_name}' df.write.mode('append').parquet( output_path, compression='snappy') # ブックマーク情報を更新 table.put_item( Item={ 'database_name': db_name, 'table_name': table_name, 'bookmark': curr_bookmark, 'updated_at': int(time.time()) } ) job.commit()
なお、GlueからSystem ManagerやDynamoDBに接続する際はVPCエンドポイントを設定して疎通できるようにしてあげる必要があるため、ご注意ください!
まとめ
ユニファではよりリッチなデータ分析を推進するため、BigQueryを採用して基盤を開発しました。 開発にあたり、各種サービスのデータはAWSのRDS内にあるため、Glueを活用することで、データ同期を実施しました。 データ分析基盤開発を検討されている方の参考になれば幸いです。
ユニファで一緒に働く仲間を募集しています!