この記事は、ユニファAdvent Calendar 2024の14日目の記事です。
Unifa Advent Calendar 2024 - Adventar

AWS re:Invent 2024で、PostgreSQL互換の分散データベース DSQLのプレビュー版が発表されましたね。
公式サイトの特徴によると
- 事実上無制限にスケール
- マルチリージョンのどこからでも書き込める
- 99.999%の高可用性
- フルマネージドでアップデートも自動
という、PostgreSQLでの運用課題に直面した時に夢にみたようなサービスが発表されました。
その一方で、Sequencesなど馴染みのある機能に非互換があるので、実務で使う場合は違いを意識する必要がありそうです。
現在、プレビュー版がオハイオとバージニア北部のリージョンで利用可能なので、気になったところを実際に少し使ってみた感想をまとめました。
注) AuroraDSQLは2024年12月の執筆現在はプレビュー版のプロダクトとなります。
大きく機能が変わる場合もあるので、ご留意の上読み進めていただければと思います。
ここからは実際にDSQLを触ってみたいと思います。 DSQLの構築については dev.classmethod.jp
を参考にさせていただきました。記事にある通り、とても簡単にセットアップすることが可能です。 構築部分は割愛し、実際にDSQLにアクセスしながらPostgreSQLとの違い見ていきたいと思います。
マルチリージョンの書き込み
冒頭の特徴にも記載したマルチリージョンで相互書き込みが可能です。 オハイオから書き込んでバージニア北部で結果を確認してみました。 同じようにバージニア北部から書き込んでオハイオからの確認もできます。
スクリーンショットだと伝わりにくいですが、実際に触るとマルチリージョンで相互に書き込めることに、直感的にすごい!と感じられます。 マネジメントコンソールのCloudShellから簡単に確認できるので、ぜひ実際に試してみて欲しいです。
- オハイオのリージョン
usersテーブルに'Aki'という名前のデータを登録します。
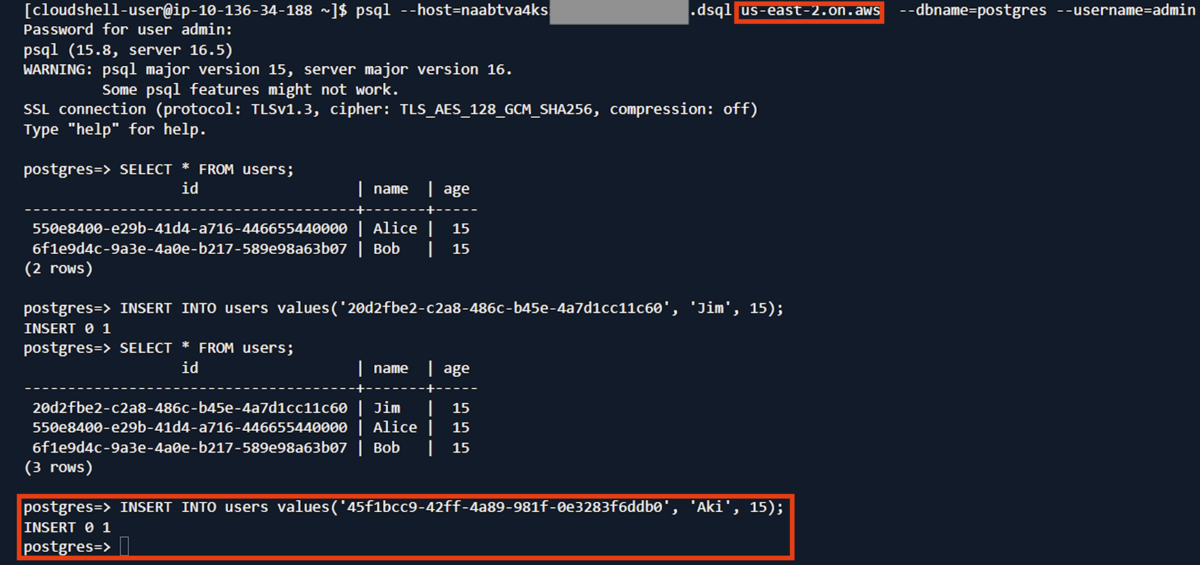
- バージニア北部のリージョン
結果を確認します。'Aki'というデータが追加されています。
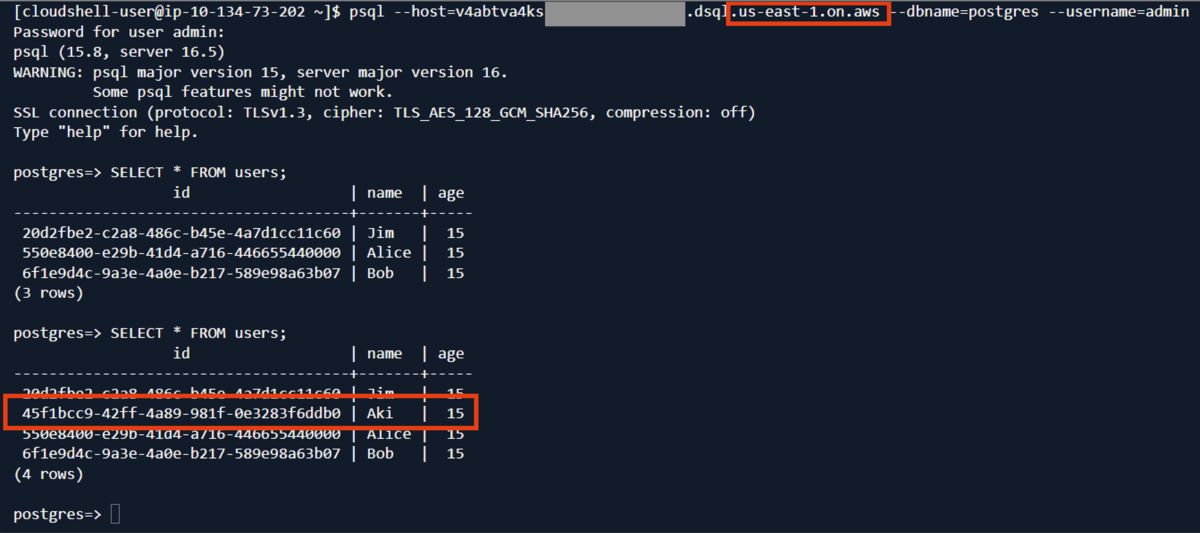
INDEXを非同期で書き込める!
DSQLには、冒頭の主要な特徴のほかにも魅力が詰まっていますが、個人的に熱いと思ったのが、CREATE INDEX ASYNCという 非同期でINDEXを作成し、トランザクションのブロックを発生させずにINDEXを作成できる機能です。 docs.aws.amazon.com
非同期でINDEXを作成し、トランザクションのブロックを発生させずにINDEXを作成できるので、大規模なテーブルでも無停止でINDEXの追加が可能となりそうです。 INDEXの追加は運用後にテーブル規模が大きくなるほどに必要に迫られることが多いので、無停止で追加できるメリットは大きいです。
実際にCREATE INDEX ASYNCを実行してみます。 インデックスが作成される代わりにjob_idが発行されました。
postgres=> CREATE TABLE groups ( id BIGINT PRIMARY KEY, name VARCHAR(100) NOT NULL ); CREATE TABLE postgres=> INSERT INTO groups VALUES(1, 'Hello GROUP!') ; INSERT 0 1 postgres=> SELECT * FROM groups; id | name ----+-------------- 1 | Hello GROUP! (1 row) postgres=> CREATE INDEX ASYNC idx_grps_name ON groups(name); job_id ---------------------------- g2fpd5j3b5f2rby2nx6k5g6u2m (1 row)
実際にトランザクションがブロックされないところまで確認すればよかったのですが、今回はざっと触ってみることを優先し、job_idの発行をみて、非同期にインデックスを作っているんだな、ということがわかったところまでを確認しました。
非互換機能
docs.aws.amazon.com をみると、Sequences、Views、Foreign keys、TRUNCATEなど、馴染み深い機能が非互換としてたくさん記載されています。
Viewテーブルがない、Foreign keysもないのも驚きでしたが、Sequencesがサポート外だったのは驚きました。 Sequencesがないので、整数型のPrimaryKeyにSERIALやBIGSERIALの指定ができなくなります。
そもそもDSQLは大容量のテーブルの場合、整数型のPrimaryKeyを使うと単一のパーティションにインサートしてボトルネックとなるので、利用はすすめておりません。 このことからも、PrimaryKeyの整数利用をDSQLは推奨していないことが伺えるので、そう考えるとSequencesが非互換なのも納得かなと思いました。
参考: Primary keys in Aurora DSQL - Amazon Aurora DSQL
For tables with high write volumes, avoid using monotonically increasing integers as primary keys, which can lead to weaker performance. Randomness in primary keys ensures even distribution of new writes across storage partitions. Instead, using monotonically increasing integers as primary keys can lead to all new inserts being directed to a single partition, which creates a bottleneck.
ほかにもPostGISやPgVectorなどの拡張機能の互換性もないので、位置情報検索やベクターデータの検索向きには使用できなさそうです。
Railsから使ってみる。ActiveRecordはほぼそのまま使えた。
DSQLはsdkが配布されていて、railsからの利用も可能です。 docs.aws.amazon.com
プレビュー版でもうRailsから使えるの!?ということに驚きつつ、 チュートリアルの通りにCRUDを実行してみました。 いくつか違いはありますが、PostgreSQLでの開発とほぼ一緒という印象です。
aws-sdkに使うAWSのアクセスキーは、必要最低限であれば
dsql:DbConnectのポリシーだけアタッチすればよさそうですが、今回は動作確認だけなので、さくっと
AmazonAuroraDSQLFullAccessをポリシーに追加しました。実運用では必要最低限のポリシーにすると良いと思います。
動作確認環境
- rails 7.2.2
- ruby 3.3.2
- 推奨環境
- ruby3.1以上
- rails は 8.0.0のインストールガイドが記載されていますが推奨というわけではなさそうで、7.2系でも動作確認可能でした。
- gem
config/initializers/adapter.rbを追加
DSQLへの接続はIAMデータベース認証が必要です。
参考 Generating an authentication token in Amazon Aurora DSQL - Amazon Aurora DSQL
To connect to Amazon Aurora DSQL with your preferred SQL client, you must generate an authentication token that you use as the password. By default, these tokens automatically expire in one hour if you use the AWS console to create it. If you use the AWS CLI or SDKs to create the token, the default is 15 minutes. The maximum is 604,800 seconds, which is one week. To connect to Aurora DSQL from your client again, you can use the same token if it hasn't expired, or you can generate a new one.
IAMデータベース認証の場合、DB接続するためのワンタイムトークンの発行が必要で、デフォルトだと15分ごとに発行が必要です。
このトークンの発行を担うのが、上記のチュートリアルにあるadapter.rbなのですが、
RailsでIAMデータベース認証を利用する場合、サードパーティのgemのpg-aws_rds_iam
の利用が前提になっているように見受けられました。
この部分
PG::AWS_RDS_IAM.auth_token_generators.add :dsql do DsqlAuthTokenGenerator.new end
でpg-aws_rds_iamをいれてないとNameErrorになる
/app/config/initializers/adapter.rb:1:in `<main>': uninitialized constant PG (NameError)
https://github.com/aws/aws-sdk-rails/issues/80 で、IAMデータベース認証のサポートに関して質問されているのですが、今のところ公式の提供はないように思えました。(深追いはしてない)
config/database.yml
今回の動作確認では以下のように設定しました。
default: &default adapter: postgresql development: <<: *default database: postgres username: admin # 検証なのでそのままadminを使った host: ****.dsql.us-east-2.on.aws sslmode: require aws_rds_iam_auth_token_generator: dsql advisory_locks: false prepared_statements: false # 検証対象外 test: <<: *default # 検証対象外 production: <<: *default
モデルを作ってCRUDを実行
rails generateで簡単なモデルを作成します。
bin/rails generate model Owner name:string city:string telephone:string
作成したモデルでプライマリーキーを明示的に記述します。
class Owner < ApplicationRecord self.primary_key = "id" end
プライマリキーを明示しないとfindで全部のカラムでWHERE句を発行してしまうようです。
Unlike postgres, Aurora DSQL creates a primary key index by including all columns of the table. This means that active record to search uses all columns of the table instead of just the primary key. So So the
.find( ) won't work because the active record tries to search by using all columns in the primary key index.
(公式ドキュメントより)
ためしに実行したら確かに全部のカラムでWHERE句が作られました。
Owner.find("6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2") # SELECT "owners".* FROM "owners" WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' AND "owners"."name" = NULL AND "owners"."city" = NULL AND "owners"."telephone" = NULL AND "owners"."created_at" = NULL AND "owners"."updated_at" = NULL LIMIT 1
作成されたマイグレーションファイルだとPrimaryKeyがデフォルトだと非互換のBIGSERIALなのでUUIDに変更します。
bin/rails db:migrate
PG::UndefinedObject: ERROR: type "bigserial" does not exist
LINE 1: CREATE TABLE "owners" ("id" bigserial primary key, "name" ch...
UUID変更前。bigserialは使えないのでエラーとなる
Primary Keyの型をuuidにします。
class CreateOwners < ActiveRecord::Migration[7.2] def change create_table :owners, id: :uuid do |t| t.string :name t.string :city t.string :telephone t.timestamps end end end
成功!
# rails db:migrate
== 20241204170102 CreateOwners: migrating =====================================
-- create_table(:owners, {:id=>:uuid})
-> 0.7571s
== 20241204170102 CreateOwners: migrated (0.7573s) ============================
create
owner = Owner.new(name: "John Smith", city: "Seattle", telephone: "123-456-7890") owner.save owner
実行結果
TRANSACTION (210.0ms) BEGIN Owner Create (406.6ms) INSERT INTO "owners" ("name", "city", "telephone", "created_at", "updated_at") VALUES ('John Smith', 'Seattle', '123-456-7890', '2024-12-05 16:55:50.174139', '2024-12-05 16:55:50.174139') RETURNING "id" TRANSACTION (266.1ms) COMMIT => #<Owner:0x00007fa7924d2290 id: "6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2", name: "John Smith", city: "Seattle", telephone: "123-456-7890", created_at: "2024-12-05 16:55:50.174139000 +0000", updated_at: "2024-12-05 16:55:50.174139000 +0000">
update
owner.update(city: "Kofu")
実行結果
TRANSACTION (363.3ms) BEGIN Owner Update (812.7ms) UPDATE "owners" SET "city" = 'Kofu', "updated_at" = '2024-12-05 16:57:42.236187' WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' TRANSACTION (234.8ms) COMMIT => true
read
Owner.find("6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2")
実行結果
Owner Load (468.8ms) SELECT "owners".* FROM "owners" WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' LIMIT 1 => #<Owner:0x00007fa791809108 id: "6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2", name: "John Smith", city: "Kofu", telephone: "123-456-7890", created_at: "2024-12-05 16:55:50.174139000 +0000", updated_at: "2024-12-05 16:57:42.236187000 +0000">
Owner.where(city: "Kofu")
実行結果
Owner Load (291.7ms) SELECT "owners".* FROM "owners" WHERE "owners"."city" = 'Kofu' /* loading for pp */ LIMIT 11 => [#<Owner:0x00007fa7918085c8 id: "6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2", name: "John Smith", city: "Kofu", telephone: "123-456-7890", created_at: "2024-12-05 16:55:50.174139000 +0000", updated_at: "2024-12-05 16:57:42.236187000 +0000">]
destroy
Owner.find("6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2").destroy!
実行結果
Owner Load (197.9ms) SELECT "owners".* FROM "owners" WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' LIMIT 1 TRANSACTION (184.0ms) BEGIN Owner Destroy (371.0ms) DELETE FROM "owners" WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' TRANSACTION (292.0ms) COMMIT => #<Owner:0x00007fa791765e40 id: "6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2", name: "John Smith", city: "Kofu", telephone: "123-456-7890", created_at: "2024-12-05 16:55:50.174139000 +0000", updated_at: "2024-12-05 16:57:42.236187000 +0000">
削除後
Owner.find("6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2")
実行結果
Owner Load (185.5ms) SELECT "owners".* FROM "owners" WHERE "owners"."id" = '6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2' LIMIT 1 Couldn't find Owner with 'id'=6b07ce7d-91be-4d4d-bc8e-22689e3e1bb2 (ActiveRecord::RecordNotFound)
おわりに
DSQLのプレビュー版を軽くさわってみて、PostgreSQLを使うように分散型のDBを今までの開発の延長線上で実装できそう、という感触でした。
一方で、DSQLのPrimaryKeyの性質上、整数型は避けたほうがよさそうな点から、既存のPostgreSQLからDSQLに載せ替えるという用途には向かなそうです。 また、外部キー制約がないのは、実装でデータ整合性を担保することでまかなえる範囲ではあるかなと思うのですが、最後の砦を失うことを意味するので、より慎重な実装が求められます。データ整合性が強く求められるプロダクトでの使用は検討したほうがよさそうかな、と感じました。
製品版の発表が楽しみだなと思いました。
ユニファでは、共に未来を創ることを目指すメンバーを募集中です!